- More on evaluation strategies
- Computing the length of a list
- However...
- How to do recursion with lower-case omega
- Neat! Can I make it easier to use?
- Generalizing
- Okay, then give me a fixed-point combinator, already!
- Fixed-point Combinators Are a Bit Intoxicating
- Watching Y in action
- Base cases, and their lack
- However...
More on evaluation strategies
Here are notes on evaluation order that make the choice of which lambda to reduce next the selection of a route through a network of links.
Computing the length of a list
How could we compute the length of a list? Without worrying yet about what lambda-calculus implementation we're using for the list, the basic idea would be to define this recursively:
the empty list has length 0
any non-empty list has length 1 + (the length of its tail)
In OCaml, you'd define that like this:
let rec get_length = fun lst ->
if lst == [] then 0 else 1 + get_length (tail lst)
in ... (* here you go on to use the function "get_length" *)
In Scheme you'd define it like this:
(letrec [(get_length
(lambda (lst) (if (null? lst) 0 [+ 1 (get_length (cdr lst))] )) )]
... ; here you go on to use the function "get_length"
)
Some comments on this:
null?is Scheme's way of sayingisempty. That is,(null? lst)returns true (which Scheme writes as#t) ifflstis the empty list (which Scheme writes as'()or(list)).cdris function that gets the tail of a Scheme list. (By definition, it's the function for getting the second member of an ordered pair. It just turns out to return the tail of a list because of the particular way Scheme implements lists.)I use
get_lengthinstead of the convention we've been following so far of hyphenated names, as inmake-list, because we're discussing OCaml code here, too, and OCaml doesn't permit the hyphenated variable names. OCaml requires variables to always start with a lower-case letter (or_), and then continue with only letters, numbers,_or'. Most other programming languages are similar. Scheme is very relaxed, and permits you to use-,?,/, and all sorts of other crazy characters in your variable names.I alternate between
[ ]s and( )s in the Scheme code just to make it more readable. These have no syntactic difference.
The main question for us to dwell on here is: What are the let rec in the OCaml code and the letrec in the Scheme code?
Answer: These work like the let expressions we've already seen, except that they let you use the variable get_length inside the body of the function being bound to it---with the understanding that it will there refer to the same function that you're then in the process of binding to get_length. So our recursively-defined function works the way we'd expect it to. In OCaml:
let rec get_length = fun lst ->
if lst == [] then 0 else 1 + get_length (tail lst)
in get_length [20; 30]
(* this evaluates to 2 *)
In Scheme:
(letrec [(get_length
(lambda (lst) (if (null? lst) 0 [+ 1 (get_length (cdr lst))] )) )]
(get_length (list 20 30)))
; this evaluates to 2
If you instead use an ordinary let (or let*), here's what would happen, in OCaml:
let get_length = fun lst ->
if lst == [] then 0 else 1 + get_length (tail lst)
in get_length [20; 30]
(* fails with error "Unbound value length" *)
Here's Scheme:
(let* [(get_length
(lambda (lst) (if (null? lst) 0 [+ 1 (get_length (cdr lst))] )) )]
(get_length (list 20 30)))
; fails with error "reference to undefined identifier: get_length"
Why? Because we said that constructions of this form:
let get_length = A
in B
really were just another way of saying:
(\get_length. B) A
and so the occurrences of get_length in A aren't bound by the \get_length that wraps B. Those occurrences are free.
We can verify this by wrapping the whole expression in a more outer binding of get_length to some other function, say the constant function from any list to the integer 99:
let get_length = fun lst -> 99
in let get_length = fun lst ->
if lst == [] then 0 else 1 + get_length (tail lst)
in get_length [20; 30]
(* evaluates to 1 + 99 *)
Here the use of get_length in 1 + get_length (tail lst) can clearly be seen to be bound by the outermost let.
And indeed, if you tried to define get_length in the lambda calculus, how would you do it?
\lst. (isempty lst) zero (add one (get_length (extract-tail lst)))
We've defined all of isempty, zero, add, one, and extract-tail in earlier discussion. But what about get_length? That's not yet defined! In fact, that's the very formula we're trying here to specify.
What we really want to do is something like this:
\lst. (isempty lst) zero (add one (... (extract-tail lst)))
where this very same formula occupies the ... position:
\lst. (isempty lst) zero (add one (
\lst. (isempty lst) zero (add one (... (extract-tail lst)))
(extract-tail lst)))
but as you can see, we'd still have to plug the formula back into itself again, and again, and again... No dice.
[At this point, some of you will recall the discussion in the first class concerning the conception of functions as sets of ordered pairs. The problem, as you will recall, was that in the untyped lambda calculus, we wanted a function to be capable of taking itself as an argument. For instance, we wanted to be able to apply the identity function to itself. And since the identity function always returns its argument unchanged, the value it should return in that case is itself:
(\x.x)(\x.x) ~~> (\x.x)
If we conceive of a function as a set of ordered pairs, we would start off like this:
1 -> 1
2 -> 2
3 -> 3
...
[1 -> 1, 2 -> 2, 3 -> 3, ..., [1 -> 1, 2 -> 2, 3 -> 3, ...,
Eventually, we would get to the point where we want to say what the identity function itself gets mapped to. But in order to say that, we need to write down the identity function in the argument position as a set of ordered pairs. The need to insert a copy of the entire function definition inside of a copy of the entire function definition inside of... is the same problem as the need to insert a complete graph of the identity function inside of the graph for the identity function.]
So how could we do it? And how do OCaml and Scheme manage to do it, with their let rec and letrec?
OCaml and Scheme do it using a trick. Well, not a trick. Actually an impressive, conceptually deep technique, which we haven't yet developed. Since we want to build up all the techniques we're using by hand, then, we shouldn't permit ourselves to rely on
let recorletrecuntil we thoroughly understand what's going on under the hood.If you tried this in Scheme:
(define get_length (lambda (lst) (if (null? lst) 0 [+ 1 (get_length (cdr lst))] )) ) (get_length (list 20 30))You'd find that it works! This is because
definein Scheme is really shorthand forletrec, not for plainletorlet*. So we should regard this as cheating, too.In fact, it is possible to define the
get_lengthfunction in the lambda calculus despite these obstacles. This depends on using the "version 3" implementation of lists, and exploiting its internal structure: that it takes a function and a base value and returns the result of folding that function over the list, with that base value. So we could use this as a definition ofget_length:\lst. lst (\x sofar. successor sofar) zeroWhat's happening here? We start with the value zero, then we apply the function
\x sofar. successor sofarto the two argumentsxnandzero, wherexnis the last element of the list. This gives ussuccessor zero, orone. That's the value we've accumuluted "so far." Then we go apply the function\x sofar. successor sofarto the two argumentsxn-1and the valueonethat we've accumulated "so far." This gives ustwo. We continue until we get to the start of the list. The value we've then built up "so far" will be the length of the list.
We can use similar techniques to define many recursive operations on lists and numbers. The reason we can do this is that our "version 3," fold-based implementation of lists, and Church's implementations of numbers, have a internal structure that mirrors the common recursive operations we'd use lists and numbers for.
As we said before, it does take some ingenuity to define functions like extract-tail or predecessor for these implementations. However it can be done. (And it's not that difficult.) Given those functions, we can go on to define other functions like numeric equality, subtraction, and so on, just by exploiting the structure already present in our implementations of lists and numbers.
With sufficient ingenuity, a great many functions can be defined in the same way. For example, the factorial function is straightforward. The function which returns the nth term in the Fibonacci series is a bit more difficult, but also achievable.
However...
Some computable functions are just not definable in this way. We can't, for example, define a function that tells us, for whatever function f we supply it, what is the smallest integer x where f x is true.
Neither do the resources we've so far developed suffice to define the Ackermann function:
A(m,n) =
| when m == 0 -> n + 1
| else when n == 0 -> A(m-1,1)
| else -> A(m-1, A(m,n-1))
A(0,y) = y+1
A(1,y) = 2+(y+3) - 3
A(2,y) = 2(y+3) - 3
A(3,y) = 2^(y+3) - 3
A(4,y) = 2^(2^(2^...2)) [where there are y+3 2s] - 3
...
Simpler functions always could be defined using the resources we've so far developed, although those definitions won't always be very efficient or easily intelligible.
But functions like the Ackermann function require us to develop a more general technique for doing recursion---and having developed it, it will often be easier to use it even in the cases where, in principle, we didn't have to.
How to do recursion with lower-case omega
Recall our initial, abortive attempt above to define the get_length function in the lambda calculus. We said "What we really want to do is something like this:
\lst. (isempty lst) zero (add one (... (extract-tail lst)))
where this very same formula occupies the ... position."
We are not going to exactly that, at least not yet. But we are going to do something close to it.
Consider a formula of the following form (don't worry yet about exactly how we'll fill the ...s):
\h \lst. (isempty lst) zero (add one (... (extract-tail lst)))
Call that formula H. Now what would happen if we applied H to itself? Then we'd get back:
\lst. (isempty lst) zero (add one (... (extract-tail lst)))
where any occurrences of h inside the ... were substituted with H. Call this F. F looks pretty close to what we're after: a function that takes a list and returns zero if it's empty, and so on. And F is the result of applying H to itself. But now inside F, the occurrences of h are substituted with the very formula H we started with. So if we want to get F again, all we have to do is apply h to itself---since as we said, the self-application of H is how we created F in the first place.
So, the way F should be completed is:
\lst. (isempty lst) zero (add one ((h h) (extract-tail lst)))
and our original H is:
\h \lst. (isempty lst) zero (add one ((h h) (extract-tail lst)))
The self-application of H will give us F with H substituted in for its free variable h.
Instead of writing out a long formula twice, we could write:
(\x. x x) LONG-FORMULA
and the initial (\x. x x) is just what we earlier called the ω combinator (lower-case omega, not the non-terminating Ω). So the self-application of H can be written:
ω (\h \lst. (isempty lst) zero (add one ((h h) (extract-tail lst))))
and this will indeed implement the recursive function we couldn't earlier figure out how to define.
In broad brush-strokes, H is half of the get_length function we're seeking, and H has the form:
\h other-arguments. ... (h h) ...
We get the whole get_length function by applying H to itself. Then h is replaced by the half H, and when we later apply h to itself, we re-create the whole get_length again.
Neat! Can I make it easier to use?
Suppose you wanted to wrap this up in a pretty interface, so that the programmer didn't need to write (h h) but could just write g for some function g. How could you do it?
Now the F-like expression we'd be aiming for---call it F*---would look like this:
\lst. (isempty lst) zero (add one (g (extract-tail lst)))
or, abbreviating:
\lst. ...g...
Here we have just a single g instead of (h h). We'd want F* to be the result of self-applying some H*, and then binding to g that very self-application of H*. We'd get that if H* had the form:
\h. (\g lst. ...g...) (h h)
The self-application of H* would be:
(\h. (\g lst. ...g...) (h h)) (\h. (\g lst. ...g...) (h h))
or:
(\f. (\h. f (h h)) (\h. f (h h))) (\g lst. ...g...)
The left-hand side of this is known as the Y-combinator and so this could be written more compactly as:
Y (\g lst. ...g...)
or, replacing the abbreviated bits:
Y (\g lst. (isempty lst) zero (add one (g (extract-tail lst))))
So this is another way to implement the recursive function we couldn't earlier figure out how to define.
Generalizing
Let's step back and fill in some theory to help us understand why these tricks work.
In general, we call a fixed point of a function f any value x such that f x is equivalent to x. For example, what is a fixed point of the function from natural numbers to their squares? What is a fixed point of the successor function?
In the lambda calculus, we say a fixed point of an expression f is any formula X such that:
X <~~> f X
What is a fixed point of the identity combinator I?
What is a fixed point of the false combinator, KI?
It's a theorem of the lambda calculus that every formula has a fixed point. In fact, it will have infinitely many, non-equivalent fixed points. And we don't just know that they exist: for any given formula, we can name many of them.
Yes, even the formula that you're using the define the successor function will have a fixed point. Isn't that weird? Think about how it might be true.
Well, you might think, only some of the formulas that we might give to the successor as arguments would really represent numbers. If we said something like:
successor make-pair
who knows what we'd get back? Perhaps there's some non-number-representing formula such that when we feed it to successor as an argument, we get the same formula back.
Yes! That's exactly right. And which formula this is will depend on the particular way you've implemented the successor function.
Moreover, the recipes that enable us to name fixed points for any given formula aren't guaranteed to give us terminating fixed points. They might give us formulas X such that neither X nor f X have normal forms. (Indeed, what they give us for the square function isn't any of the Church numerals, but is rather an expression with no normal form.) However, if we take care we can ensure that we do get terminating fixed points. And this gives us a principled, fully general strategy for doing recursion. It lets us define even functions like the Ackermann function, which were until now out of our reach. It would also let us define arithmetic and list functions on the "version 1" and "version 2" implementations, where it wasn't always clear how to force the computation to "keep going."
OK, so how do we make use of this?
Recall again our initial, abortive attempt above to define the get_length function in the lambda calculus. We said "What we really want to do is something like this:
\lst. (isempty lst) zero (add one (... (extract-tail lst)))
where this very same formula occupies the ... position."
If we could somehow get ahold of this very formula, as an additional argument, then we could take the argument and plug it into the ... position. Something like this:
\self (\lst. (isempty lst) zero (add one (self (extract-tail lst))) )
This is an abstract of the form:
\self. BODY
where BODY is the expression:
\lst. (isempty lst) zero (add one (self (extract-tail lst)))
containing an occurrence of self.
Now consider what would be a fixed point of our expression \self. BODY? That would be some expression X such that:
X <~~> (\self.BODY) X
Beta-reducing the right-hand side, we get:
X <~~> BODY [self := X]
Think about what this says. It says if you substitute X for self in our formula BODY:
\lst. (isempty lst) zero (add one (X (extract-tail lst)))
what you get is "equivalent" to (that is, convertible with) X itself. That is, the X inside the above expression is equivalent to the whole expression. So the expression does, in a sense, contain itself!
Let's go over that again. If we had a fixed point X for our expression \self. ...self..., then by the definition of a fixed-point, this has to be true:
X <~~> (\self. ...self...) X
but beta-reducing the right-hand side, we get something of the form:
X <~~> ...X...
So on the right-hand side we have a complex expression, that contains some occurrences of whatever our fixed-point X is, and X is convertible with that very complex, right-hand side expression.
So we really can define get_length in the way we were initially attempting, in the bare lambda calculus, where Scheme and OCaml's souped-up let rec constructions aren't primitively available. (In fact, what we're doing here is the natural way to implement let rec.)
This all turns on having a way to generate a fixed-point for our "starting formula":
\self (\lst. (isempty lst) zero (add one (self (extract-tail lst))) )
Where do we get it?
Suppose we have some fixed-point combinator
Ψ. That is, some function that returns, for any expression f we give it as argument, a fixed point for f. In other words:
Ψ f <~~> f (Ψ f)Then applying Ψ to the "starting formula" displayed above would give us our fixed point X for the starting formula:
Ψ (\self (\lst. (isempty lst) zero (add one (self (extract-tail lst))) ))And this is the fully general strategy for defining recursive functions in the lambda calculus. You begin with a "body formula":
...self...
containing free occurrences of self that you treat as being equivalent to the body formula itself. In the case we're considering, that was:
\lst. (isempty lst) zero (add one (self (extract-tail lst)))
You bind the free occurrence of self as: \self. BODY. And then you generate a fixed point for this larger expression:
Ψ (\self. BODY)using some fixed-point combinator Ψ.
Isn't that cool?
Okay, then give me a fixed-point combinator, already!
Many fixed-point combinators have been discovered. (And some fixed-point combinators give us models for building infinitely many more, non-equivalent fixed-point combinators.)
Two of the simplest:
Θ′ ≡ (\u f. f (\n. u u f n)) (\u f. f (\n. u u f n))
Y′ ≡ \f. (\u. f (\n. u u n)) (\u. f (\n. u u n))Θ′ has the advantage that f (Θ′ f) really reduces to Θ′ f. Whereas f (Y′ f) is only convertible with Y′ f; that is, there's a common formula they both reduce to. For most purposes, though, either will do.
You may notice that both of these formulas have eta-redexes inside them: why can't we simplify the two \n. u u f n inside Θ′ to just u u f? And similarly for Y′?
Indeed you can, getting the simpler:
Θ ≡ (\u f. f (u u f)) (\u f. f (u u f))
Y ≡ \f. (\u. f (u u)) (\u. f (u u))I stated the more complex formulas for the following reason: in a language whose evaluation order is call-by-value, the evaluation of Θ (\self. BODY) and Y (\self. BODY) will in general not terminate. But evaluation of the eta-unreduced primed versions will.
Of course, if you define your \self. BODY stupidly, your formula will never terminate. For example, it doesn't matter what fixed point combinator you use for Ψ in:
Ψ (\self. \n. self n)When you try to evaluate the application of that to some argument M, it's going to try to give you back:
(\n. self n) M
where self is equivalent to the very formula \n. self n that contains it. So the evaluation will proceed:
(\n. self n) M ~~>
self M ~~>
(\n. self n) M ~~>
self M ~~>
...
You've written an infinite loop!
However, when we evaluate the application of our:
Ψ (\self (\lst. (isempty lst) zero (add one (self (extract-tail lst))) ))to some list L, we're not going to go into an infinite evaluation loop of that sort. At each cycle, we're going to be evaluating the application of:
\lst. (isempty lst) zero (add one (self (extract-tail lst)))
to the tail of the list we were evaluating its application to at the previous stage. Assuming our lists are finite (and the implementations we're using don't permit otherwise), at some point one will get a list whose tail is empty, and then the evaluation of that formula to that tail will return zero. So the recursion eventually bottoms out in a base value.
Fixed-point Combinators Are a Bit Intoxicating
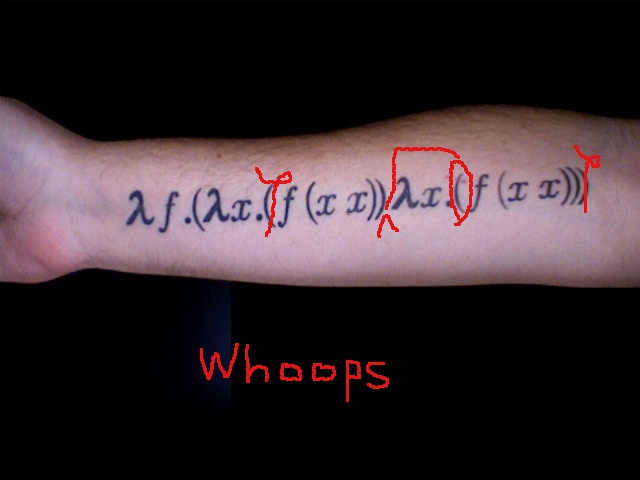
There's a tendency for people to say "Y-combinator" to refer to fixed-point combinators generally. We'll probably fall into that usage ourselves. Speaking correctly, though, the Y-combinator is only one of many fixed-point combinators.
I used Ψ above to stand in for an arbitrary fixed-point combinator. I don't know of any broad conventions for this. But this seems a useful one.
As we said, there are many other fixed-point combinators as well. For example, Jan Willem Klop pointed out that if we define L to be:
\a b c d e f g h i j k l m n o p q s t u v w x y z r. (r (t h i s i s a f i x e d p o i n t c o m b i n a t o r))
then this is a fixed-point combinator:
L L L L L L L L L L L L L L L L L L L L L L L L L L
Watching Y in action
For those of you who like to watch ultra slow-mo movies of bullets
piercing apples, here's a stepwise computation of the application of a
recursive function. We'll use a function sink, which takes one
argument. If the argument is boolean true (i.e., \x y.x), it
returns itself (a copy of sink); if the argument is boolean false
(\x y. y), it returns I. That is, we want the following behavior:
sink false ~~> I
sink true false ~~> I
sink true true false ~~> I
sink true true true false ~~> I
So we make sink = Y (\f b. b f I):
1. sink false
2. Y (\fb.bfI) false
3. (\f. (\h. f (h h)) (\h. f (h h))) (\fb.bfI) false
4. (\h. [\fb.bfI] (h h)) (\h. [\fb.bfI] (h h)) false
5. [\fb.bfI] ((\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))) false
6. (\b.b[(\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))]I) false
7. false [(\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))] I
--------------------------------------------
8. I
So far so good. The crucial thing to note is that as long as we
always reduce the outermost redex first, we never have to get around
to computing the underlined redex: because false ignores its first
argument, we can throw it away unreduced.
Now we try the next most complex example:
1. sink true false
2. Y (\fb.bfI) true false
3. (\f. (\h. f (h h)) (\h. f (h h))) (\fb.bfI) true false
4. (\h. [\fb.bfI] (h h)) (\h. [\fb.bfI] (h h)) true false
5. [\fb.bfI] ((\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))) true false
6. (\b.b[(\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))]I) true false
7. true [(\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))] I false
8. [(\h. [\fb.bsI] (h h))(\h. [\fb.bsI] (h h))] false
We've now arrived at line (4) of the first computation, so the result is again I.
You should be able to see that sink will consume as many trues as
we throw at it, then turn into the identity function after it
encounters the first false.
The key to the recursion is that, thanks to Y, the definition of
sink contains within it the ability to fully regenerate itself as
many times as is necessary. The key to ending the recursion is that
the behavior of sink is sensitive to the nature of the input: if the
input is the magic function false, the self-regeneration machinery
will be discarded, and the recursion will stop.
That's about as simple as recursion gets.
Base cases, and their lack
As any functional programmer quickly learns, writing a recursive
function divides into two tasks: figuring out how to handle the
recursive case, and remembering to insert a base case. The
interesting and enjoyable part is figuring out the recursive pattern,
but the base case cannot be ignored, since leaving out the base case
creates a program that runs forever. For instance, consider computing
a factorial: n! is n * (n-1) * (n-2) * ... * 1. The recursive
case says that the factorial of a number n is n times the
factorial of n-1. But if we leave out the base case, we get
3! = 3 * 2! = 3 * 2 * 1! = 3 * 2 * 1 * 0! = 3 * 2 * 1 * 0 * -1! ...
That's why it's crucial to declare that 0! = 1, in which case the recursive rule does not apply. In our terms,
fac = Y (\fac n. iszero n 1 (fac (predecessor n)))
If n is 0, fac reduces to 1, without computing the recursive case.
There is a well-known problem in philosophy and natural language semantics that has the flavor of a recursive function without a base case: the truth-teller paradox (and related paradoxes).
(1) This sentence is true.
If we assume that the complex demonstrative "this sentence" can refer to (1), then the proposition expressed by (1) will be true just in case the thing referred to by this sentence is true. Thus (1) will be true just in case (1) is true, and (1) is true just in case (1) is true, and so on. If (1) is true, then (1) is true; but if (1) is not true, then (1) is not true.
Without pretending to give a serious analysis of the paradox, let's
assume that sentences can have for their meaning boolean functions
like the ones we have been working with here. Then the sentence John
is John might denote the function \x y. x, our true.
Then (1) denotes a function from whatever the referent of this
sentence is to a boolean. So (1) denotes \f. f true false, where
the argument f is the referent of this sentence. Of course, if
f is a boolean, f true false <~~> f, so for our purposes, we can
assume that (1) denotes the identity function I.
If we use (1) in a context in which this sentence refers to the
sentence in which the demonstrative occurs, then we must find a
meaning m such that I m = I. But since in this context m is the
same as the meaning I, so we have m = I m. In other words, m is
a fixed point for the denotation of the sentence (when used in the
appropriate context).
That means that in a context in which this sentence refers to the sentence in which it occurs, the sentence denotes a fixed point for the identity function. Here's a fixed point for the identity function:
Y I
(\f. (\h. f (h h)) (\h. f (h h))) I
(\h. I (h h)) (\h. I (h h)))
(\h. (h h)) (\h. (h h)))
ω ω
&Omega
Oh. Well! That feels right. The meaning of This sentence is true
in a context in which this sentence refers to the sentence in which
it occurs is Ω, our prototypical infinite loop...
What about the liar paradox?
(2) This sentence is false.
Used in a context in which this sentence refers to the utterance of
(2) in which it occurs, (2) will denote a fixed point for \f.neg f,
or \f l r. f r l, which is the C combinator. So in such a
context, (2) might denote
Y C
(\f. (\h. f (h h)) (\h. f (h h))) I
(\h. C (h h)) (\h. C (h h)))
C ((\h. C (h h)) (\h. C (h h)))
C (C ((\h. C (h h))(\h. C (h h))))
C (C (C ((\h. C (h h))(\h. C (h h)))))
...
And infinite sequence of Cs, each one negating the remainder of the
sequence. Yep, that feels like a reasonable representation of the
liar paradox.
See Barwise and Etchemendy's 1987 OUP book, The Liar: an essay on truth and circularity for an approach that is similar, but expressed in terms of non-well-founded sets rather than recursive functions.
However...
You should be cautious about feeling too comfortable with
these results. Thinking again of the truth-teller paradox, yes,
Ω is a fixed point for I, and perhaps it has
some a privileged status among all the fixed points for I, being the
one delivered by Y and all (though it is not obvious why Y should have
any special status).
But one could ask: look, literally every formula is a fixed point for
I, since
X <~~> I X
for any choice of X whatsoever.
So the Y combinator is only guaranteed to give us one fixed point out
of infinitely many---and not always the intuitively most useful
one. (For instance, the squaring function has zero as a fixed point,
since 0 * 0 = 0, and 1 as a fixed point, since 1 * 1 = 1, but Y
(\x. mul x x) doesn't give us 0 or 1.) So with respect to the
truth-teller paradox, why in the reasoning we've
just gone through should we be reaching for just this fixed point at
just this juncture?
One obstacle to thinking this through is the fact that a sentence normally has only two truth values. We might consider instead a noun phrase such as
(3) the entity that this noun phrase refers to
The reference of (3) depends on the reference of the embedded noun phrase this noun phrase. It's easy to see that any object is a fixed point for this referential function: if this pen cap is the referent of this noun phrase, then it is the referent of (3), and so for any object.
The chameleon nature of (3), by the way (a description that is equally good at describing any object), makes it particularly well suited as a gloss on pronouns such as it. In the system of Jacobson 1999, pronouns denote (you guessed it!) identity functions...
Ultimately, in the context of this course, these paradoxes are more useful as a way of gaining leverage on the concepts of fixed points and recursion, rather than the other way around.